평소 PS를 할 때, 자료구조 는 크게 신경 쓰지 않았던 것 같다.
그러다가 이번 Dijkstra 문제를 풀면서 자료구조에 따라 시간초과가 발생할 수 있음을 직접 경험해 보며, 앞으로의 PS에는 자료구조도 한번 더 고민해 보기를 바라며 기록을 남긴다.
문제 파악 문제가 된 코드는 Dijkstra 함수 구현 부분이다.
물론 제대로 구현된 코드는 아님을 알고 있다. 순회를 할 때 queue를 만든 자료구조를 제외하고는 똑같은 코드이다.
ArrayList
fun dijkstra(N: Int, X: Int, vertex: Array<ArrayList<Int>>): Array<Int> {
val INF = 1_000_001
val dist = Array(N, { INF })
val visited = Array(N, { true })
val queue = arrayListOf<Int>()
var s = X
dist[s] = 0
queue.add(s)
do {
s = queue.removeFirst()
visited[s] = false
vertex[s].forEach {
if (visited[it]) {
queue.add(it)
dist[it] = min(dist[it], dist[s] + 1)
}
}
} while (queue.isNotEmpty())
return dist
}LinkedList
fun dijkstra(N: Int, X: Int, vertex: Array<ArrayList<Int>>): Array<Int> {
val INF = 1_000_001
val dist = Array(N, { INF })
val visited = Array(N, { true })
val queue = LinkedList<Int>()
var s = X
dist[s] = 0
queue.add(s)
do {
s = queue.removeFirst()
visited[s] = false
vertex[s].forEach {
if (visited[it]) {
queue.add(it)
dist[it] = min(dist[it], dist[s] + 1)
}
}
} while (queue.isNotEmpty())
return dist
}두 코드 모두에서 queue를 사용하지만 각각 ArrayList 와 LinkedList로 차이를 보이며, queue의 맨 처음 것을 제거하고 맨 마지막에 추가하는 동일한 방식의 코드이다.
문제점으로는 ArrayList 로 queue를 구현하였을 때는 시간초과가 발생하였지만, LinkedList 로 queue를 구현했을 때는 시간초과가 발생하지 않았다.
원인 분석 두 자료구조( ArrayList, LinkedList)는 Java의 List interface를 구현한 Collections의 일종인데, 내부적인 동작 방식을 보면 차이를 보인다.
ArrayList의 경우 데이터의 변화(추가/삭제)가 발생하면 임시 배열을 생성하는 반면 LinkedList는 노드 간의 연결을 변화시킨다.
ArrayList
https://docs.oracle.com/javase/7/docs/api/java/util/ArrayList.html
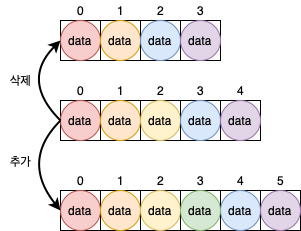
ArrayList의 구조를 보면 간단하게 배열을 이용하여 구현된 것을 알 수 있다.
하지만 이러한 방식은 검색에서는 효과적일 수는 있지만, 자료의 추가/삭제에는 효율적이지 못하다.
데이터의 추가 및 삭제가 발생하면 기존 배열로부터 임시 배열을 만들어 작업을 수행하기에 최악의 경우에는 O(N)의 시간이 걸린다. 즉, 데이터의 밀고 당기는 작업이 필요하다. 추가로 배열은 동적으로 늘어나는 것이 아니라, 배열이 꽉 찼을 경우 더 큰 배열을 만들어 옮겨야 하기에 loss가 크다.
하지만 검색 차원에서는 배열의 시작 주소에 index만을 더해 data가 존재하는 곳의 주소를 바로 알 수 있기 때문에 O(1)의 시간이 걸린다.
LinkedList
https://docs.oracle.com/javase/7/docs/api/java/util/LinkedList.html
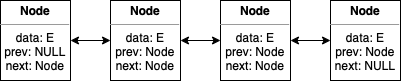
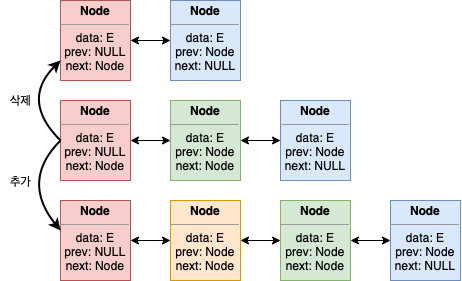
LinkedList의 구조를 보면 data를 저장하는 노드간의 연결을 통해 리스트로 구현된 것을 알 수 있다.
하지만 이러한 방식은 자료의 추가/삭제에서는 효과적일 수는 있지만, 검색에는 효율적이지 못하다.
데이터의 추가 및 삭제가 발생하면 새로운 노드를 만들거나 삭제하고 next 노드를 갱신하면 된다. 하지만 검색을 하기 위해서는 sequential 하게 접근해야 하기에 최악의 경우에는 O(N)의 시간이 걸린다.
기존 배열로부터 임시 배열을 만들어 작업을 수행하기에 최악의 경우에는 O(N)의 시간이 걸린다. 즉, 데이터의 밀고 당기는 작업이 추가로 필요하다.
결론 도출
작업 종류 비교
추가/삭제 ArrayList < LinkedList
검색 ArrayList > LinkedList
List를 구성해야 하는 작업이 많다면 LinkedList 를,
구성된 List에서 검색 작업이 많다면 ArrayList를,
사용하는 것이 좋아 보인다.